ExcelをPython(openpyxl)で操作する - PandasのDataFrameに変換
以前、openpyxl を使ってExcelファイルの操作に関する記事をいくつか書きました。
- ExcelをPython(openpyxl)で操作する - ファイルの新規作成、保存、開く
- ExcelをPython(openpyxl)で操作する - シートの作成、シート属性値変更
- ExcelをPython(openpyxl)で操作する - セルの読み書き
今回はExcelのデータを Pandas のデータ形式に変換する方法を紹介します。
なぜ Pandas かというと、 Pandas によって、様々な データ分析のための処理を簡単に行える からです。
事前準備
モジュールのインストール
まずは必要なモジュールをインストールします。
pip install openpyxl pandasサンプルデータの準備
次にサンプルデータを準備します。今回は以下のようなデータを持った sample.xlsx を作成します。
1行目にヘッダ行が ない 以下のような no_header シートと
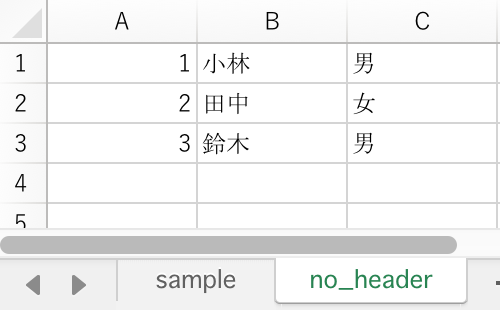
1行目にヘッダ行が ある 、 sample シートを準備します。
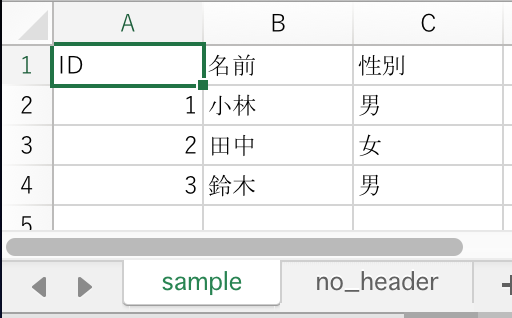
openpyxl から PandasのDataFrameへ変換
では早速、openpyxl でシートのデータを読み取り、 DataFrame に変換しましょう。
DataFrame は、Pandas 上で2次元のデータを表す場合に使います。
Excelのデータは行と列の2次元データなので、openpyxl の Worksheet オブジェクトを DataFrame オブジェクトに変換するイメージです。
ヘッダー行なしデータの場合
ヘッダー行のないシートの場合には、 DataFrame に ws.values を渡すだけでできます。
1from openpyxl import load_workbook
2import pandas as pd
3
4# ワークブックを読み込む
5wb = load_workbook('sample.xlsx')
6# no_headerシートにアクセスする
7ws = wb['no_header']
8
9# value値をDataFrameに変換
10df = pd.DataFrame(ws.values)変換できているか確認してみましょう。
1# DataFrame内の最初の3行のみ表示
2df.head(3)| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 小林 | 男 |
| 1 | 2 | 田中 | 女 |
| 2 | 3 | 鈴木 | 男 |
ヘッダー行がないので、列番号がヘッダーとして表示されます。
ヘッダー行ありデータの場合
ヘッダー行ありのデータの場合には少し、処理を追加する必要があります。
DataFrame 作成時に columns オプションを指定することで、カラム名を与える事ができます。
このとき、 columns オプションに与える配列の長さ(=列の数)と、DataFrame 生成時の実体データの配列の長さ(=列の数)は
等しい必要があります。
1from openpyxl import load_workbook
2import pandas as pd
3
4wb = load_workbook('sample.xlsx')
5ws = wb['sample']
6
7data = ws.values
8# 最初の行をヘッダーとして取得する
9columns = next(data)[0:]
10# 以降のデータからDataFrameを作成する
11df = pd.DataFrame(data, columns=columns)同様に結果を見てみましょう。
1# DataFrame内の最初の3行のみ表示
2df.head(3)| ID | 名前 | 性別 | |
|---|---|---|---|
| 0 | 1 | 小林 | 男 |
| 1 | 2 | 田中 | 女 |
| 2 | 3 | 鈴木 | 男 |
きちんとヘッダー名も表示されました。
PandasでExcelファイルを読み込む
先程は openpyxl で読み込んだデータを DataFrame に変換しました。
実はこの操作は Pandas の read_excel 関数を使うことで同様の処理ができます。
内部的には xlrd や openpyxl に依存しているので、モジュールのインストールが必要です。
1pip install openpyxl pandas xlrd以下のように read_excel 関数を呼び出すだけで完了です。
1import pandas as pd
2
3df = pd.read_excel('sample.xlsx', sheet_name='sample')
4df.head()まとめ
Excelのデータを Pandas の DataFrame として扱う方法を紹介しました。
openpyxl の Worksheet オブジェクトから DataFrame へ変換する方法もあれば、Pandas の read_excel 関数を用いる方法もあります。
特にこだわりがないのであれば、 read_excel 関数を使った方がシンプルだと思います。
