Use openpyxl - Convert to DataFrame in Pandas
Introduction
Previously, I wrote several articles on working Excel files using openpyxl.
- Use openpyxl - open, save Excel files in Python
- Use openpyxl - create a new Worksheet, change sheet property in Python
- Use openpyxl - read and write Cell in Python
In this article, I introduce how to convert openpyxl data to Pandas data format called DataFrame.
Preparation
Install modules
First, install module with pip command.
pip install openpyxl pandasMake sample data
Second, create a new file named sample.xlsx including the following data.
- Workbook has a sheet named
no_headerthat doesn’t have header line.
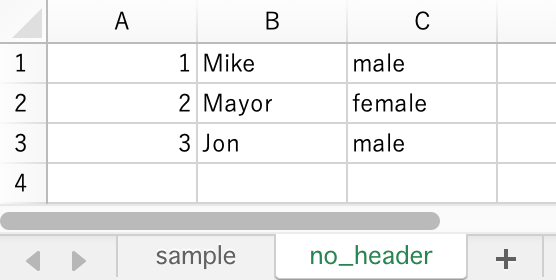
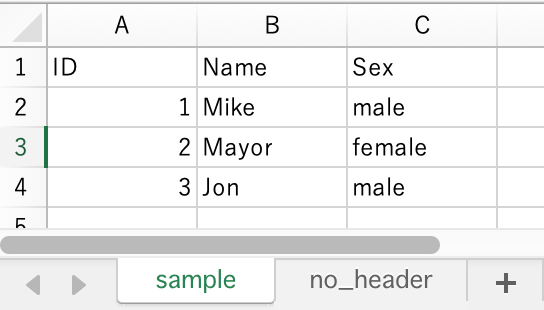
- Workbook has a sheet named
samplethat has a header line.
Convert openpyxl object to DataFrame
Load Excel data with openpyxl and convert to DataFrame. DataFrame is used to represent 2D data on Pandas.
Since Excel data is also 2D data expressed by rows and columns, Worksheet object in [openpyxl] (https://openpyxl.readthedocs.io/en/stable/index.html) can be converted to Pandas DataFrame object.
Data without header line
When converting a file that has no header line, give values property on Worksheet object to DataFrame constructor.
1from openpyxl import load_workbook
2import pandas as pd
3
4# Load workbook
5wb = load_workbook('sample.xlsx')
6# Access to a worksheet named 'no_header'
7ws = wb['no_header']
8
9# Convert to DataFrame
10df = pd.DataFrame(ws.values)Check the result.
1df.head(3)| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | Mike | male |
| 1 | 2 | Mayor | female |
| 2 | 3 | Jon | male |
The column number is displayed as a header.
Data with header line
In case of a file that has a header line, it is necessary to change processing. When creating a DataFrame object, specify column name with columns option. At this time, the length of array given columns option must be equal to length of columns in DataFrame.
The sample code is as follows.
1from openpyxl import load_workbook
2import pandas as pd
3
4wb = load_workbook('sample.xlsx')
5ws = wb['sample']
6
7data = ws.values
8# Get the first line in file as a header line
9columns = next(data)[0:]
10# Create a DataFrame based on the second and subsequent lines of data
11df = pd.DataFrame(data, columns=columns)Check the result.
1df.head(3)| ID | Name | Sex | |
|---|---|---|---|
| 0 | 1 | Mike | male |
| 1 | 2 | Mayor | female |
| 2 | 3 | Jon | male |
The column name is displayed.
Loading Excel file easier with read_excel function
Using the read_excel function in Pandas, we can do the same processing. To use read_excel function, install xlrd and openpyxl.
1pip install openpyxl pandas xlrdCall read_excel function as below.
1import pandas as pd
2
3df = pd.read_excel('sample.xlsx', sheet_name='sample')
4df.head()Conclusion
It is available to
- Convert
Worksheetobject with or without headers toDataFrameobject - Make it simpler with
read_excelfunction in Pandas
