Use PyPDF2 - which PyPDF 2 or PyPDF 3 should be used?
Introduction
In previous article, we can extract text on a PDF file using PyPDF2.
I will introduce PyPDF3 in this article.
PyPDF2 and PyPDF3 exist
When I looked for various usage of PyPDF2, I found the follwing commnet in StackOverflow.

The PyPDF2 has been stopped since 3 years ago?! And, new version PyPDF3 exists?! Really?
Which should I use PyPDF2 or PyPDF3 ??
Check the PyPI
Does PyPDF3 exist on PyPI? Check with pip command.
This is PyPDF2.
1pip search PyPDF2
2> PyPDF2 (1.26.0) - PDF toolkitThis is PyPDF3.
1pip search PyPDF3
2> PyPDF3 (1.0.1) - Pure Python PDF toolkitBoth are really present!!
What is PyPDF3 ?
In this section, I show my understanding about PyPDF3 by reading roadmap on Github and another resources.
Volunteers have started PyPDF3 project that is based on PyPDF2 because PyPDF2 has not been updated since 3 years ago.
Initial goals are to fully implement existing features and fix some of the most critical bugs/performance issues from PyPDF2 before moving on to new functionality.
However, development is not active as far as seeing the commit log.
All of the story is discussed in a certain github issue
As a further investigation, I got to one github issue.
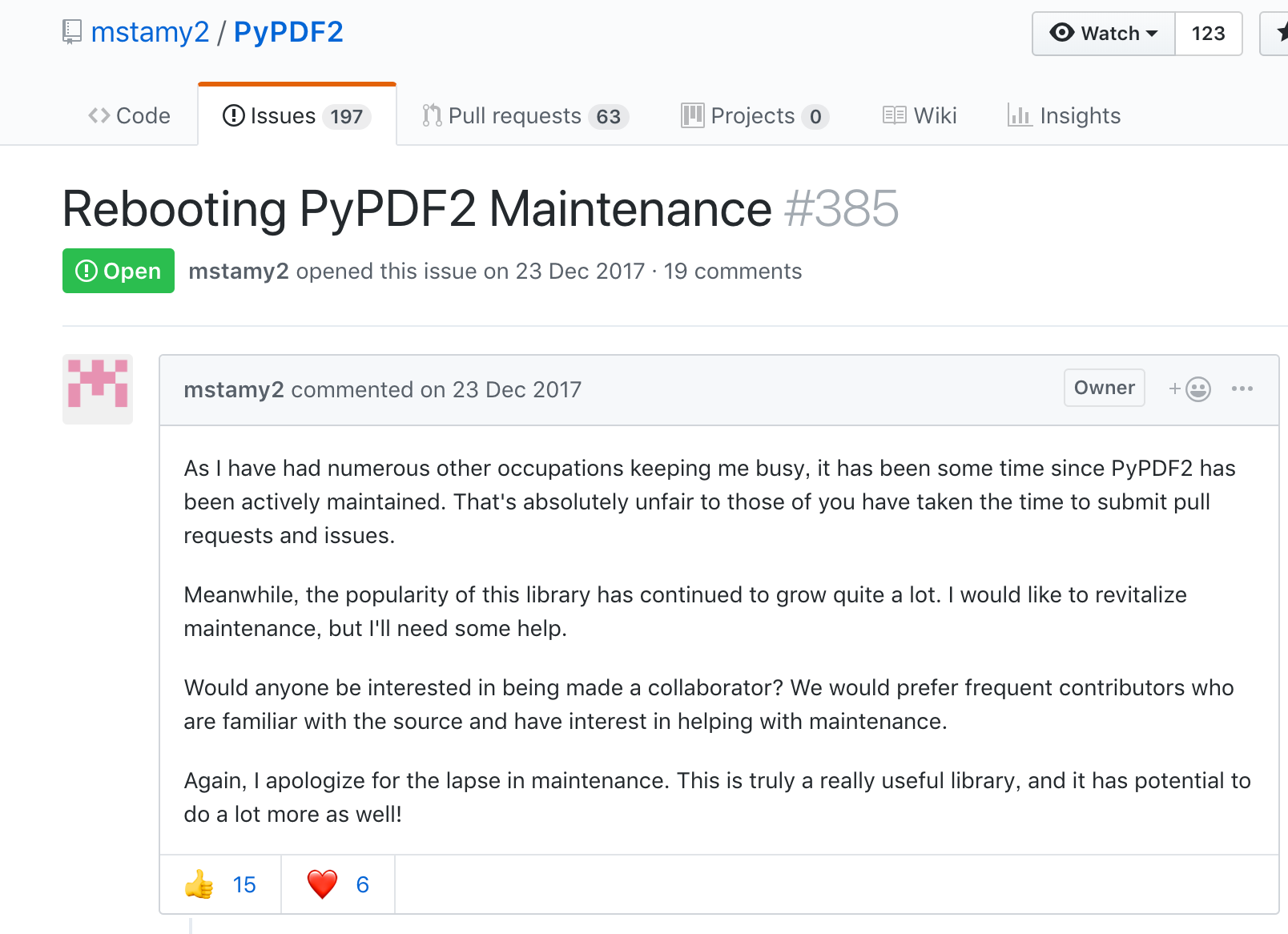
In summarize..
- PyPDF2 core maintainer had not updated it because of busy
- However he has decided to restart to update PyPDF2
- Developers also discuss PyPDF3 in that issues
Conclusion
We can use PyPDF2 without problems.
I checked issues and pull requests in PyPDF2 repository and I understand that PyPDF2 is still alive.
