AWS Batchで前処理をしてGlue CrawlerでAthenaのスキーマを作成する
以前、 S3にエクスポートされたCloudWatch LogsのファイルをGlueのCrawlerでETLしようとして轟沈した話 でGlueを少し触ってみたのですが、今回はAWS Batchで前処理 + Glue CrawlerでAthenaのスキーマを自動生成しました、という話をしようと思います。
モチベーション:データを容易に検索したい
PUSH配信基盤の構築やレコメンドエンジン、その他諸々の機械学習関係の処理を普段使っていない人でも、 何らかのシステム開発に携わっているのであれば、システムが垂れ流すデータを見て、それを「いい感じに見たいなー」と思うことは良くあります。
今回は一般的なWeb APIのシステムにおいて、
- 障害の調査をより簡易にしたい
- リクエストの傾向を把握したい
といったモチベーションがあり、実装してみることにしました。
Tableau や Redash といった所謂BIツールで可視化してもいいのですが、 今回のケースでは検索を簡単にすれば十分なので、 Athenaで検索できること をゴールに設定しました。
やってみる
アーキテクチャ概要
さっそくやってみましょう。下図のようなアーキテクチャを構築しました。
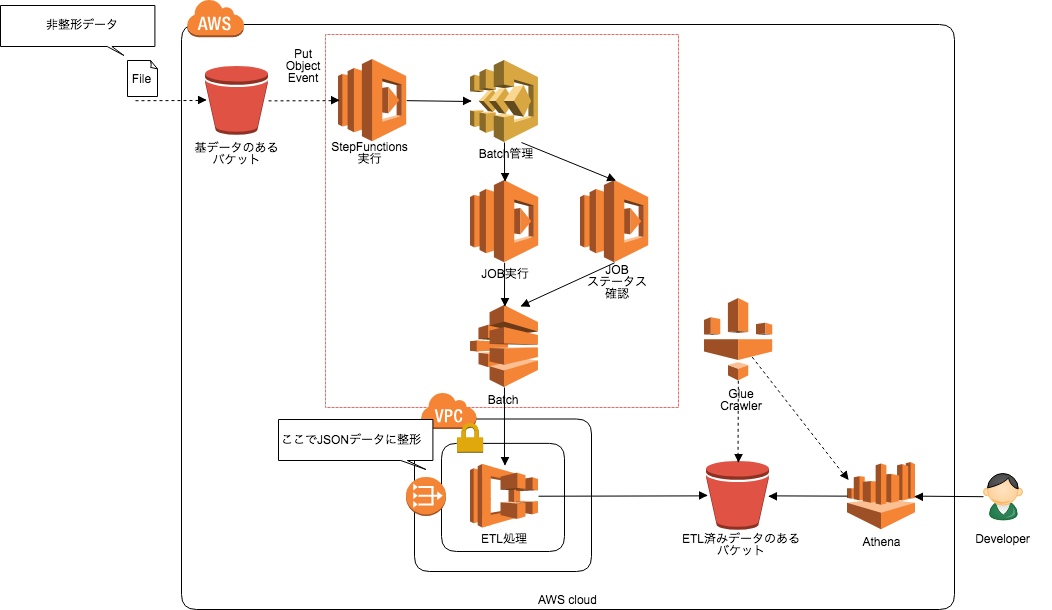
大まかな処理の流れを説明すると
- S3バケットにファイルが置かれる
- Object Put EventでLambdaが起動し、StepFunctionsを実行
- StepfunctionsがAWS Batchのステートメントを管理
- AWS Batchの実行
- Batch Jobのステータス確認
- AWS Batchで起動されるECSで前処理を実施し、成果物をS3にPUT
- Glue CrawlerがS3のファイルからAthenaスキーマを自動生成
なお、図中の赤枠部分はクラスメソッドさんの 「AWS Step Functionsでジョブ・ステータス・ポーリングを実装する」 を参考に実装していますので、 説明は割愛します。
バケットの作成
まずは図中のS3バケットを2つ作成します。用途としては以下です。
- 整形前データ置き場
- 整形後データ置き場(Glue Crawlerが参照するバケット)
AWS Batchの実装
前処理を行うAWS Batchの実装をしましょう。 Batchと言いつつも、内部的にはECSが起動して処理を行うため、AWS Batchの設定にはECSに対する一定の理解も必要です。
ECRの作成
まずは、AWS Batchで実行させるECSコンテナのDockerイメージをECRにPushします。
今回は前処理をPython 3.6で実行させたいので、 python:3.6.5-alpine のイメージを使ってDockerfileを作成します。
コンテナ内の /opt/etl 配下にpythonプログラムを置くイメージです。
1FROM python:3.6.5-alpine
2
3MAINTAINER soudegesu
4
5COPY ./etl /opt/etl
6COPY ./requirements.txt /opt/requirements.txt
7
8RUN pip install --upgrade pip
9RUN pip install -r /opt/requirements.txtビルドしたdocker imageをECRにpushすればOKです。
コンピューティング環境の設定
AWS Batchから起動させるコンピューティング環境の設定をします。 これはAWS batchから起動するECSインスタンスの設定です。
Terraformで設定例を書くと以下のようになります。
1resource "aws_batch_compute_environment" "etl" {
2 compute_environment_name = "etl"
3 compute_resources {
4 instance_role = "${ECSインスタンスのRole}"
5 instance_type = [
6 ${EC2インスタンスタイプ}"
7 ]
8 max_vcpus = 16
9 min_vcpus = 2
10 desired_vcpus = 2
11 security_group_ids = ["${SecurityGroupのID}"]
12 subnets = ["${SubnetのID}"]
13 type = "EC2"
14 }
15 service_role = "arn:aws:iam::${アカウント番号}:role/service-role/AWSBatchServiceRole"
16 type = "MANAGED"
17}ジョブキューの作成
次にジョブキューの設定を行います。キューに格納されたジョブの実行の優先順位や、実行時のコンピューティングリソースの紐付けを定義しておきます。
Terraformで設定例を書くと以下のようになります。
1resource "aws_batch_job_queue" "etl" {
2 name = "etl"
3 state = "ENABLED"
4 priority = 1
5 compute_environments = [
6 "${aws_batch_compute_environment.etl.arn}"
7 ]
8}バッチのジョブ定義
次に実行するジョブの定義をします。
ジョブと言っても、ECSのタスク定義の情報に加えて、コンテナ起動後に実行するコマンドを書いたりします。
Terraformで設定例を書くと以下のようになります。
コンテナ内で任意のプログラムを実行する場合には command プロパティ部に設定を行います。
引数部分に Ref:: という見慣れないものがありますが、これは後述します。
1resource "aws_batch_job_definition" "etl" {
2 name = "etl"
3 type = "container"
4 container_properties = <<EOF
5{
6 "command": ["python",
7 "/opt/etl/main.py",
8 "-b",
9 "Ref::bucket",
10 "-k",
11 "Ref::objKey"
12 ],
13 "environment": [
14 {
15 "name": "TMP",
16 "value": "/tmp"
17 },
18 {
19 "name": "UPLOAD_BUCKET",
20 "value": "${バケット名}"
21 }
22 ],
23 "image": "${var.account_id}.dkr.ecr.${var.region}.amazonaws.com/etl:${var.image_tag}",
24 "memory": 1024,
25 "vcpus": 2,
26 "ulimits": [
27 {
28 "hardLimit": 1024,
29 "name": "nofile",
30 "softLimit": 1024
31 }
32 ]
33}
34EOF
35
36}なお、ここで実行される main.py の処理概要は以下になります。
- 基データのあるバケットからデータを取得する
- データレコードは JSONフォーマット に加工する
- ETL済みデータのあるバケットへアップロードする
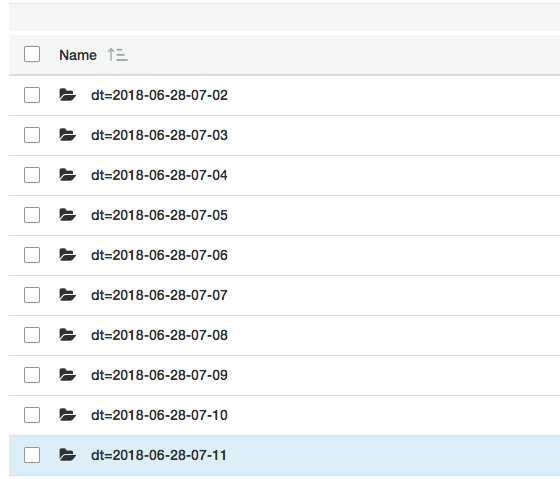
- S3バケットに Hiveフォーマット(
dt=yyyy-MM-dd-HH-mm) でパーティション(フォルダ)を作成 する - ファイルは
.gzでアップロードする
- S3バケットに Hiveフォーマット(
ジョブを実行するLambdaの実装
AWS Batchのジョブを実行するだけのサンプルコードを書きます。
1import json
2import boto3
3import logging
4import os
5
6logger = logging.getLogger(__name__)
7logger.setLevel(logging.INFO)
8
9def lambda_handler(event, context):
10
11 job_name = os.environ['JOB_NAME']
12 job_queue = os.environ['JOB_QUEUE']
13 job_definition = os.environ['JOB_DEFINITION']
14 bucket_name = os.environ['BUCKET_NAME']
15 obj_key = os.environ['OBJECT_KEY']
16 parameters = {
17 'bucket': str(bucket_name),
18 'objKey': str(obj_key)
19 }
20
21 batch = boto3.client('batch')
22 try:
23 response = batch.submit_job(jobQueue=job_queue, jobName=job_name, jobDefinition=job_definition, parameters=parameters)
24 jobId = response['jobId']
25 return {
26 'jobId': jobId
27 }
28 except Exception as e:
29 logger.error(e)
30 raise Exception('Error submitting Batch Job')要点としては submit_job 関数の parameters 引数で渡されたデータが、
先程のバッチジョブ定義の Ref:: を置換することで、動的なデータの受け渡しを実現しています。
(今回のケースで言えば bucket と objKey が置換されます)
1 "command": ["python",
2 "/opt/etl/main.py",
3 "-b",
4 "Ref::bucket",
5 "-k",
6 "Ref::objKey"
7 ],ここまで来れば、ETL済みのバケットへ以下のような構成でデータがアップロードされているはずです。
Glue CrawlerからAthenaのスキーマを作成する
GlueのCrawlerはデータソースに任意のデータベースやS3を指定することができ、 そのデータからAthenaのスキーマを自動生成してくれる機能を持っています。
Terraform AWS Providerが2018/06にGlue Crawlerに対応したこともあり、Terraformで書いてみましょう。
まずはデータベースの設定です。これはAthenaのデータベースになります。
1resource "aws_glue_catalog_database" "sample" {
2 name = "${データベース名}"
3}次にCrawlerの設定です。
今回のユースケースであれば role は最低限 AWSGlueServiceRole がついていれば問題ありません。
schedule にてCrawlerが対象のS3のパスを見に行くスケジュールの指定ができますし、
スキーマ変更があった場合の振る舞いを定義(今回は「データが無くなっていたら削除する」に指定)できます。
1resource "aws_glue_crawler" "sample" {
2 database_name = "${aws_glue_catalog_database.sample.name}"
3 name = "${Crawler名}"
4 role = "${Glue用のRole}"
5
6 s3_target {
7 path = "${S3バケットのパス}"
8 }
9
10 schedule = "cron(0 21 * * ? *)"
11
12 schema_change_policy = {
13 delete_behavior = "DELETE_FROM_DATABASE"
14 }
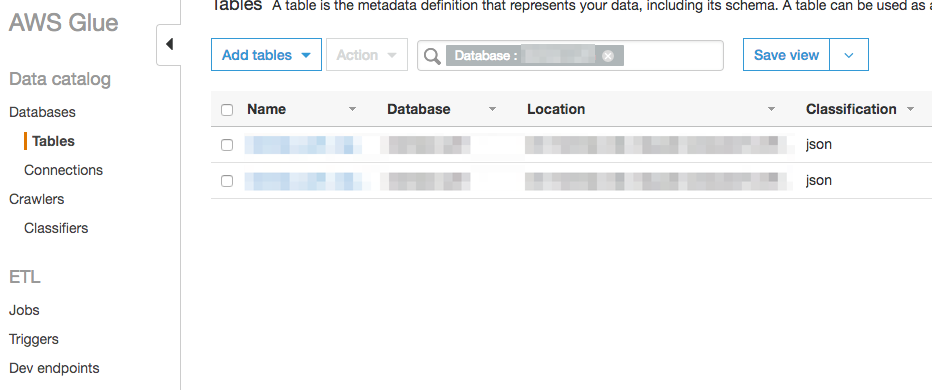
15}Crawlerを実行すると、「Databases」 > 「Tables」 の中にいくつかデータテーブルができていることがわかります。 これがAthenaのテーブルとリンクします。
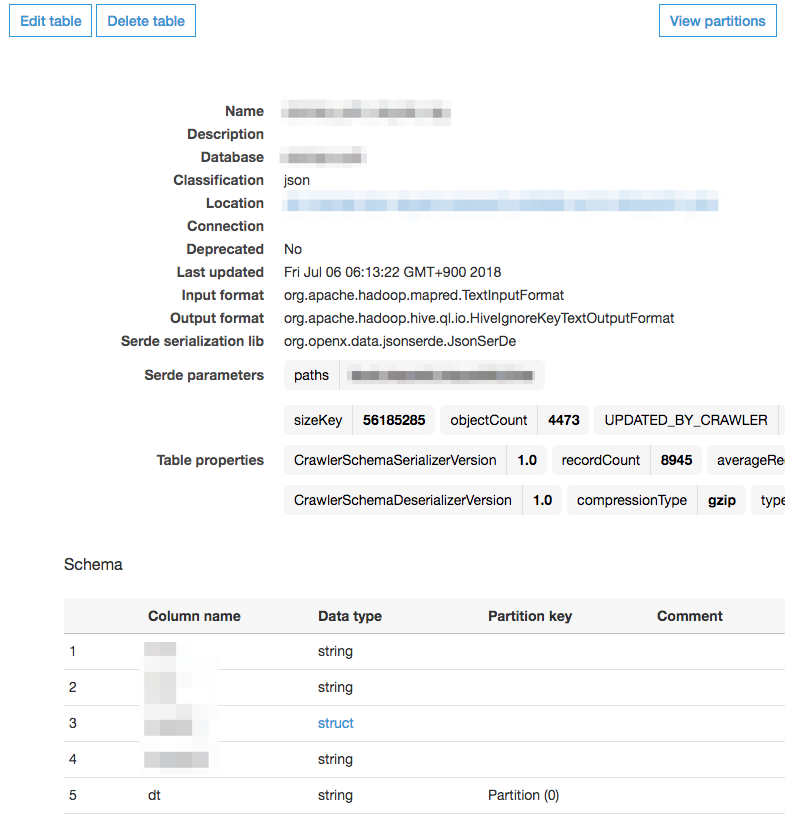
作成されたテーブルの詳細を見てみると、Classification の部分が json となっています。
パーティション内のデータをJSON形式のデータと認識してスキーマを定義してくれたということです。
ネストされたJSONプロパティは struct として定義されていることもわかります。
なお、コンソールからテーブルを選択して、「Action」 > 「View data」 を選択すると、Athenaコンソールの紐づいているデータベースへ画面遷移します。
ここまで来れば、後は普通にクエリを書けるようになりますね。
まとめ
今回はAWS Batchと AWS Glueを用いてAthenaのスキーマを生成するまでを行いました。 AWS BatchはStepFunctionsと組み合わせて利用することで、バッチ処理結果に伴うハンドリングができるので、堅めの処理をしたいときにはいいかもしれません。
今回のユースケースに限って言えば、AWS BatchではなくFargateの方が適切だったようにも思えます。(2018/7にFargateが東京リージョンに来ました)
予めGlueのCrawlerは、前処理でS3パーティションやデータ構造を工夫してあげるだけで、データカタログ(Athenaのスキーマ)を勝手に作ってくれるので大変便利です。
今回は、データカタログを作るまでで終わりますが、そこからGlue本来のSparkへの処理に繋げることもできますし、SageMakerでパーティションのS3バケットを覗き込ませることもできるでしょう。
Glueの採用事例が更に増えていくことに期待ですね!
参考にさせていただいたサイト
- AWS Step Functionsでジョブ・ステータス・ポーリングを実装する
- AWS Black Belt Online Seminar 2017 AWS Batch
- ジョブ定義のパラメータ - AWS Batch
