PandasでDataFrameの追加や結合をする
以前書いた ExcelをPython(openpyxl)で操作する - PandasのDataFrameに変換 では Pandas でExcelファイルの読み込みについて説明しました。
今回は読み込んだ複数のDataFrameの扱いについて説明します。
データを横方向に追加する
DataFrameを横方向に追加する、つまり、別の列として追加する方法を説明します。
ただし、前提として、マージする側とされる側の行数が同じで、かつ、データの順序が同じである必要があります。
例えば、以下のような sample シートのデータと
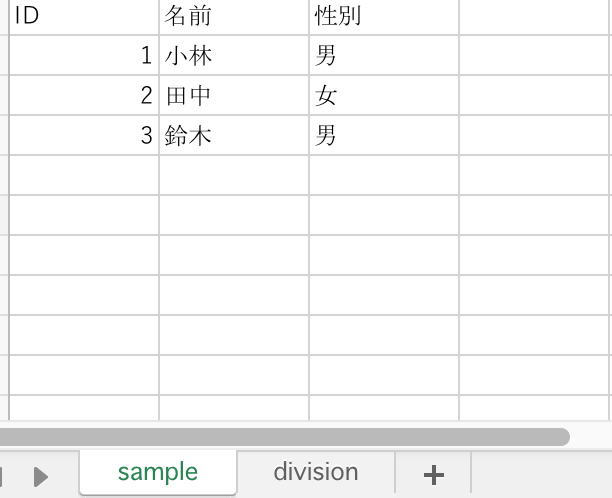
以下のような division シートのデータを一つの行のデータに統合します。
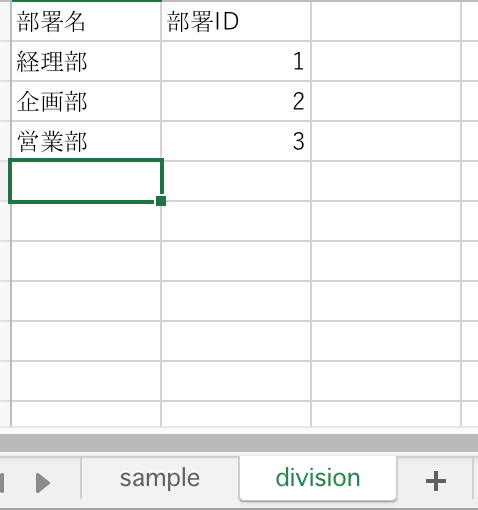
concat 関数を用いて、オプション axis=1 を指定すると、複数の DataFrame を横方向に統合できます。
1import pandas as pd
2
3# sample シートを読み込む
4df_sample = pd.read_excel('sample.xlsx', sheet_name='sample')
5# division シートを読み込む
6df_division = pd.read_excel('sample.xlsx', sheet_name='division')
7
8# axis=1で横方向に追加
9result = pd.concat([df_sample, df_division], axis=1)
10result.head()| ID | 名前 | 性別 | 部署ID | 部署名 | |
|---|---|---|---|---|---|
| 0 | 1 | 小林 | 男 | 1 | 経理部 |
| 1 | 2 | 田中 | 女 | 2 | 企画部 |
| 2 | 3 | 鈴木 | 男 | 3 | 営業部 |
データを縦方向に追加する
逆に縦方向にデータを追加する場合には、 concat 関数のオプションで axis=0 を指定します(デフォルト値なので、省略しても構いません)。
1import pandas as pd
2
3# sample シートを読み込む
4df_sample = pd.read_excel('sample.xlsx', sheet_name='sample')
5
6# axis=0で行を追加
7# 今回は df_sample のDataFrameを2回縦に繋げる
8result = pd.concat([df_sample, df_sample], axis=0, ignore_index=True)
9# headはデフォルトで5行しか出力しないため、10行出力に変更
10result.head(10)| ID | 名前 | 性別 | |
|---|---|---|---|
| 0 | 1 | 小林 | 男 |
| 1 | 2 | 田中 | 女 |
| 2 | 3 | 鈴木 | 男 |
| 3 | 1 | 小林 | 男 |
| 4 | 2 | 田中 | 女 |
| 5 | 3 | 鈴木 | 男 |
ignore_index=True オプションを指定することで、結合前の行のインデックス番号を無視し、新たにインデックス番号を振り直します。
データを結合する
merge 関数を使います。複数の DataFrame に共通して存在するキーを使って、データを結合できます。
これはSQLに馴染みのある人であればピンと来ると思いますが、SQLのJOIN句と概念的に同じです。
そのため、正規化された複数の DataFrame に対して merge 関数を使うケースが多いです。
以下のような sample シートのデータと
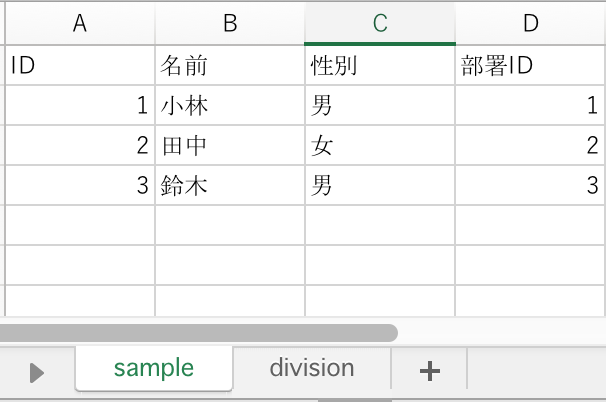
以下のような division シートのデータがあり、
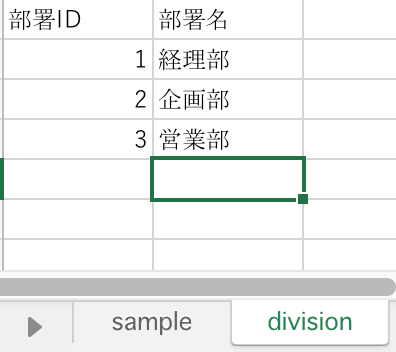
部署ID をキーとして、一つのデータに結合してみましょう。
1import pandas as pd
2
3# sample シートを読み込む
4df_sample = pd.read_excel('sample.xlsx', sheet_name='sample')
5# division シートを読み込む
6df_division = pd.read_excel('sample.xlsx', sheet_name='division')
7
8# 部署IDをキーにJOINする
9result = df_sample.merge(df_division, on='部署ID')
10result.head()sample シートのデータを軸として、division シートのデータを結合した行が出力されます。
| ID | 名前 | 性別 | 部署ID | 部署名 | |
|---|---|---|---|---|---|
| 0 | 1 | 小林 | 男 | 1 | 経理部 |
| 1 | 2 | 田中 | 女 | 2 | 企画部 |
| 2 | 3 | 鈴木 | 男 | 3 | 営業部 |
merge 関数には how オプションがあり、結合方法を指定できます。
デフォルトは left となっており、LEFT JOIN を意味します。
なお、 merge 関数と似たような機能を持つ join 関数も存在します。
join 関数は、データを結合するためのキーを インデックスとして指定する必要があります。 これには set_index 関数を使います。
以下のように書くことができます。
1result = df_sample.join(df_division.set_index('部署ID'), on='部署ID')まとめ
concat 関数を使えば、DataFrame 同士を縦横に追加できます。
一方で正規化されたデータの DataFrame の結合は merge または join 関数でできます。
個人的にはオプションの多い merge 関数のほうがオススメです。
