PDFをPython(PyPDF2)で操作する - PyPDF2とPyPDF3のどちらを使うと良いのか
以前に書いた以下の記事では、PyPDF2 を用いて、PDFファイルからテキスト情報を抽出するまでを行うことができました。
今回は少し毛色が違いますが、PyPDF3 について触れたいと思います。
PyPDF2 と PyPDF3 が存在する問題
PyPDF2 の調査を進めていく過程で、とあるStackOverflowのコメント に目を奪われました。

PyPDF2 が3年前に死んでいる。。だと!? そして、PyPDF3 なる、新たなバージョンが存在しているのか。。?
我々はどちらを使うのが正しいのであろうか
pip で確認してみる
本当に PyPDF3 は存在するのか。
pip コマンドでモジュールをインストールできなければ、そもそも検討の俎上にも上がらないであろう。
こちらは PyPDF2 。
1pip search PyPDF2
2> PyPDF2 (1.26.0) - PDF toolkitこちらは PyPDF3 。
1pip search PyPDF3
2> PyPDF3 (1.0.1) - Pure Python PDF toolkitどうやら存在するようです。なんてこったい。
PyPDF3 は何者なのか
PyPDF3 のGithubのページに記載された Roadmap 、先程のStackOverflowのコメント や他の調査結果も踏まえて自分の理解をまとめます。
PyPDF3 発足の経緯
3年程前から PyPDF2 の更新が止まってしまったため、有志が PyPDF2 を forkして PyPDF3 プロジェクトを始めた。
PyPDF3の機能
PyPDF2 が抱えていた パフォーマンスの問題 や 多くの不具合 、 加えて、 不足している機能 や 既存機能の改善 を PyPDF3 では解決する予定、とのこと。
ただし開発は活発ではない
一方で、PyPDF3 のコミットログを見ても、あまり開発は進んでいないように伺えます。 PyPDF2 と比較して、GithubのStarの数も少ないですし。 これは一体どういうことだ。。
解決:PyPDF2のissueにすべてはあった
その後、更に調査を進めていくと一本のissueにたどり着いた。
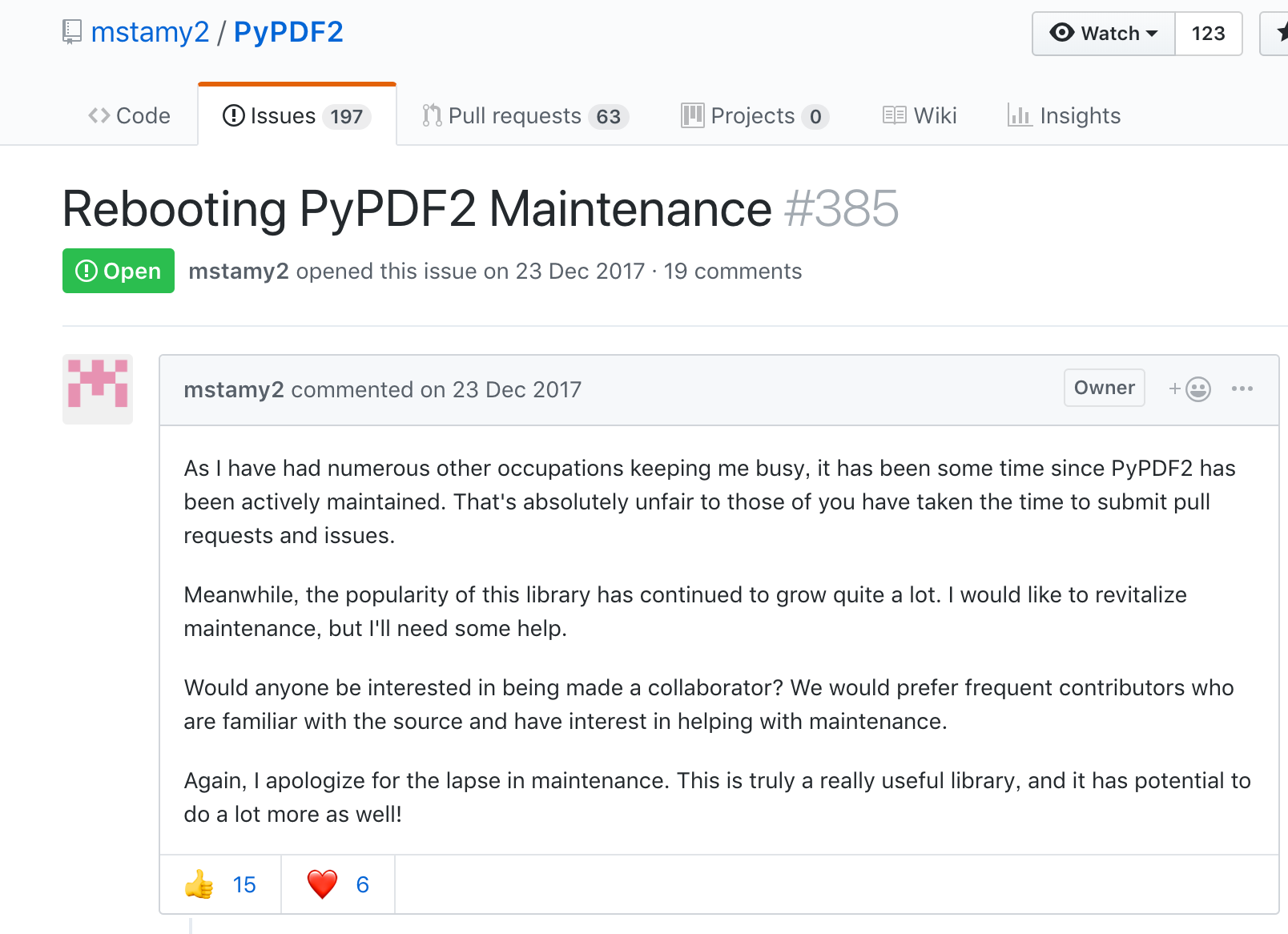
サマリー部分を要約すると下記のような感じです。
- 忙しくて全くメンテナンスできていなかった
- 気づかないうちに、PyPDF2 がめちゃめちゃ人気が出ていたので、改めて活動を再開しようと思う
- しかし、手がまわらないので、誰か collaborator になってくれないか?
また、issueの中のディスカッションで、PyPDF3 についても触れられており、 2018/12現在においては PyPDF3 自体の立ち位置や今後の進め方を検討中 というステータスのようでした。
他のissueやpull requestも確認しましたが、PyPDF2 は活発に開発が再開されているようでした。
まとめ
PyPDF3 と PyPDF2 のどちらを使えば良いのか、という今回のテーマについては、
PyPDF2 を使えば良い
が結論になりました。
ただし、「PyPDF3 を今後どうように進めるか」の議論は未決着なので、PyPDF2 を使うタイミングで、Rebooting PyPDF2 Maintenance #385 の流れを確認しておくと安全でしょう。
